이번주차는 지난 4주 간 공부한 것을 바탕으로 딥러닝 모델을 구축하고 AI HUB에서 제공하는 화자 인식용 데이터를 이용하여 학습시켜 보았습니다.
AI HUB에서 제공하는 화자 인식용 데이터는 전체크기가 8Gb 이상이기 때문에 맛보기용 데이터로 학습시켰습니다.
AI-Hub
샘플 데이터 ? ※샘플데이터는 데이터의 이해를 돕기 위해 별도로 가공하여 제공하는 정보로써 원본 데이터와 차이가 있을 수 있으며, 데이터에 따라서 민감한 정보는 일부 마스킹(*) 처리가 되
www.aihub.or.kr
사용한 라이브러리 목록입니다
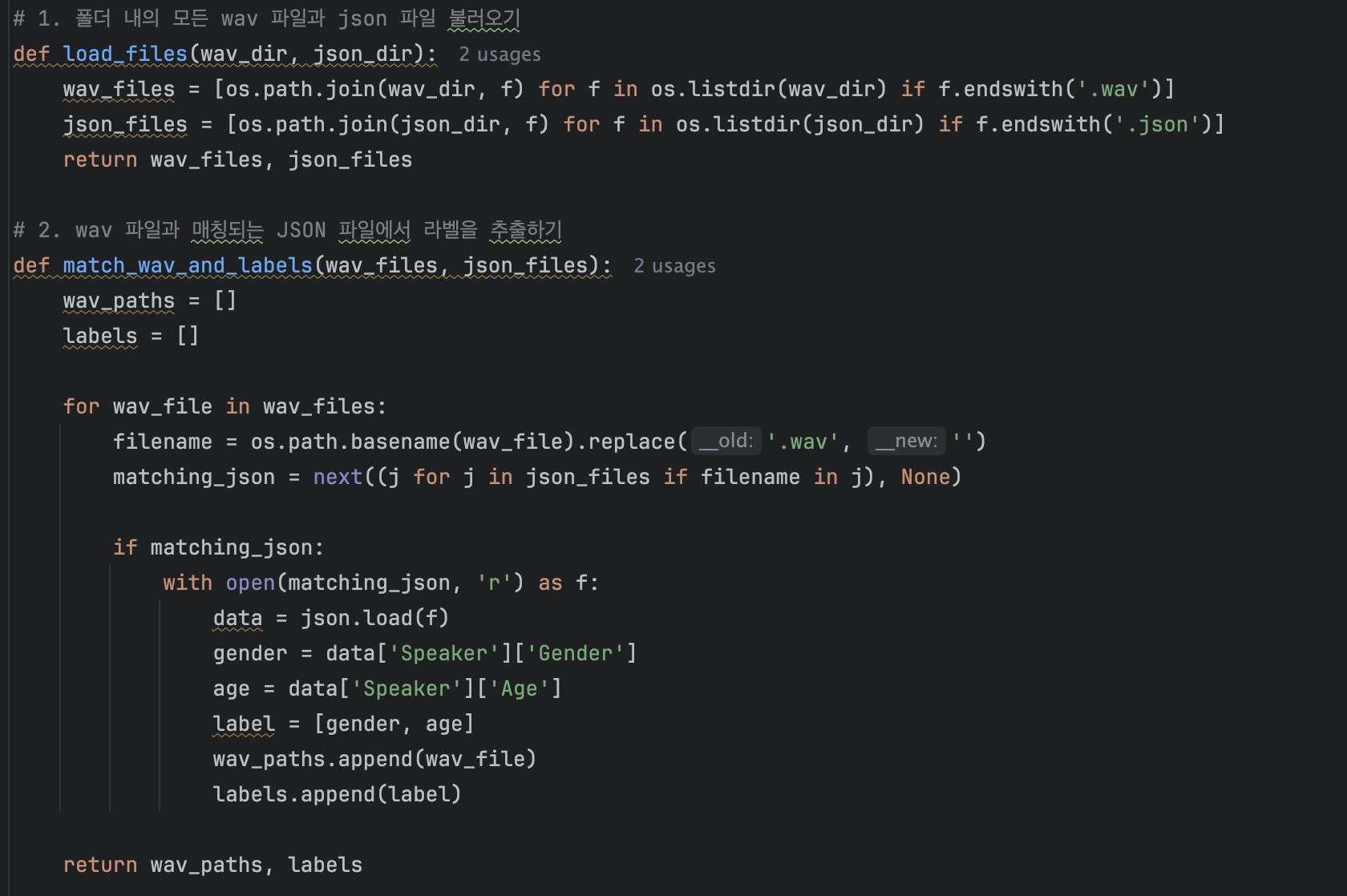
폴더 내의 모든 wav파일과 json파일을 불러오는 함수를 os 라이브러리를 이용해 정의했습니다.
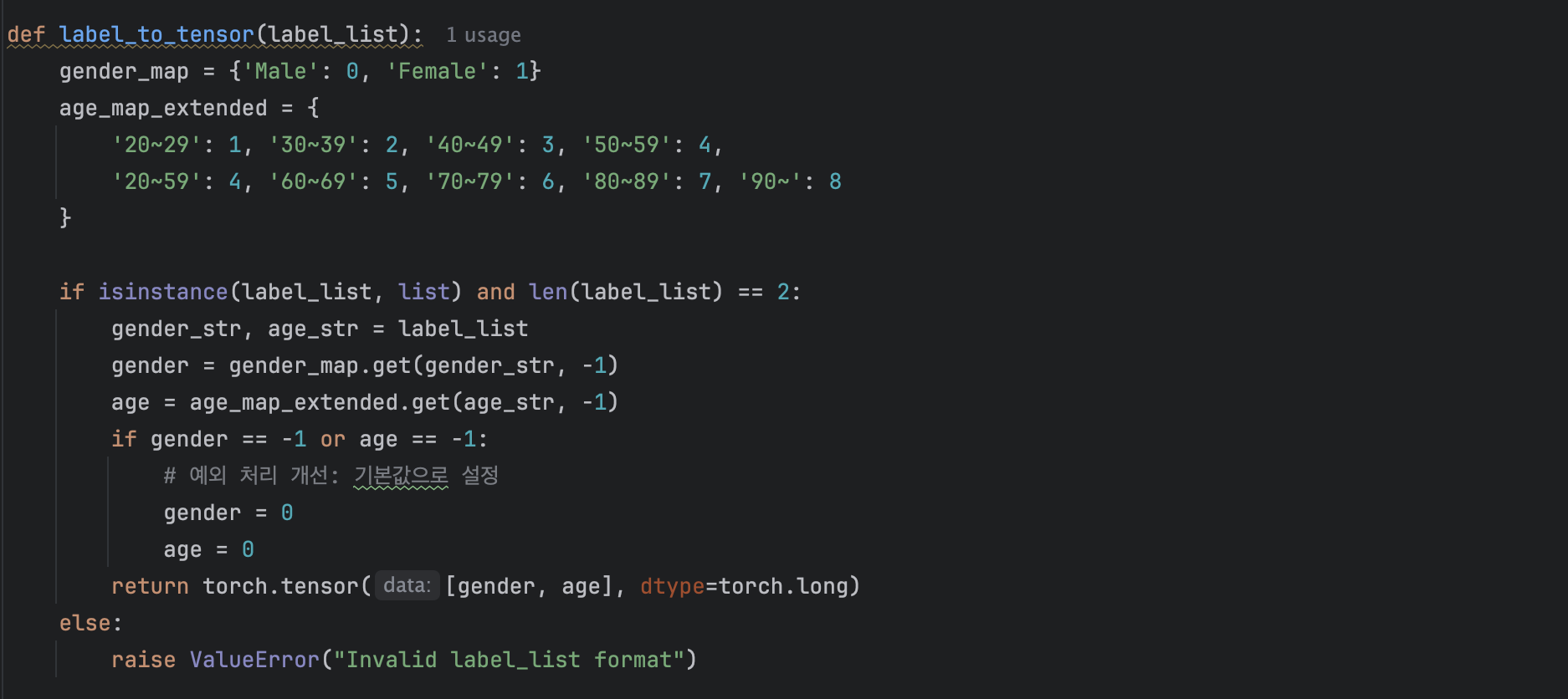
wav파일의 정보가 기록되어있는 json파일에는 Age와 Gender항목이 있었으며 이 두가지 항목을 label로 지정해 학습했습니다.
다만 데이터중 20~59 같은 넓은 범위의 Age항목도 있어 mapping을 해줬습니다.
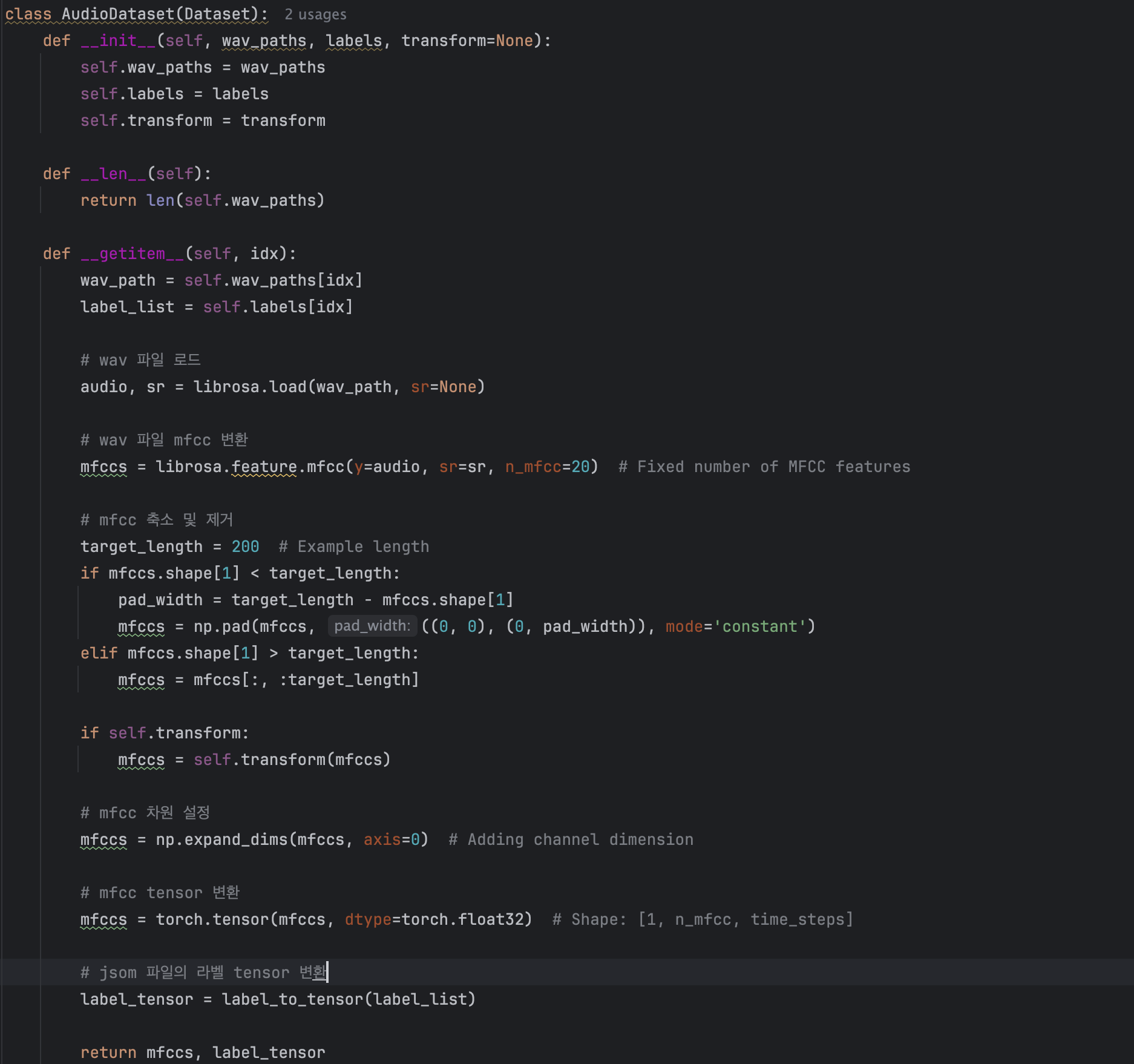
AudioDataset이라는 클래스를 정의하여 Librosa 라이브러리를 이용해 wav 형식의 데이터를 mfcc로 표현하는 과정을 거치도록 정의해주었습니다.
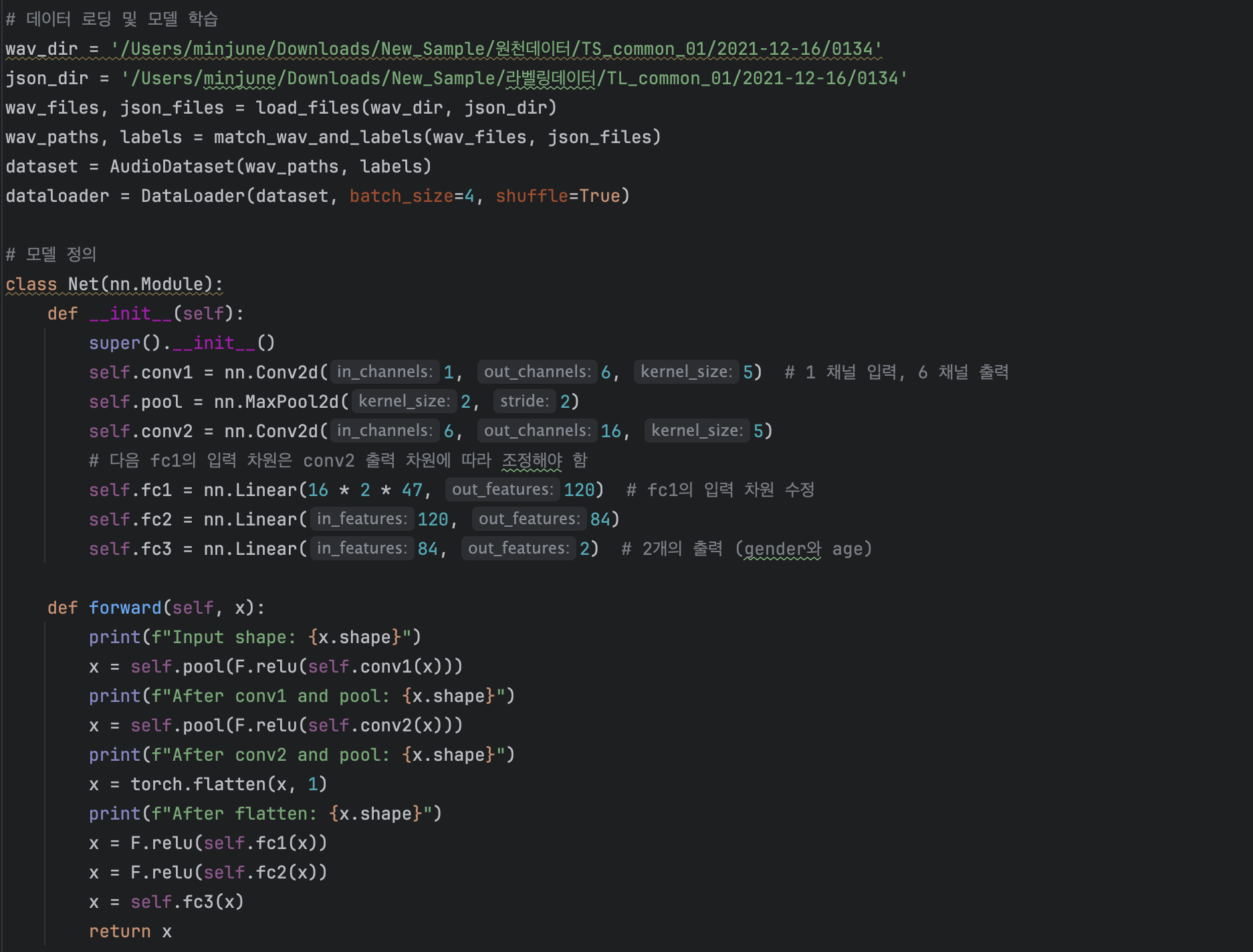
각각의 변수에 파일의 경로와 torch.utils.data 모듈을 이용하여 DataLoader를 설정했습니다.
딥러닝 모델은 이전 주차에서 진행한 'Pytorch 딥러닝: 60분만에 끝내기' 의 모델에서 레이어의 in_features 와 out_features 그리고
conv1의 채널 설정을 변경해 사용했습니다.

손실 함수와 학습 루프는 이전 주차의 모델에서 사용한 것과 유사합니다.
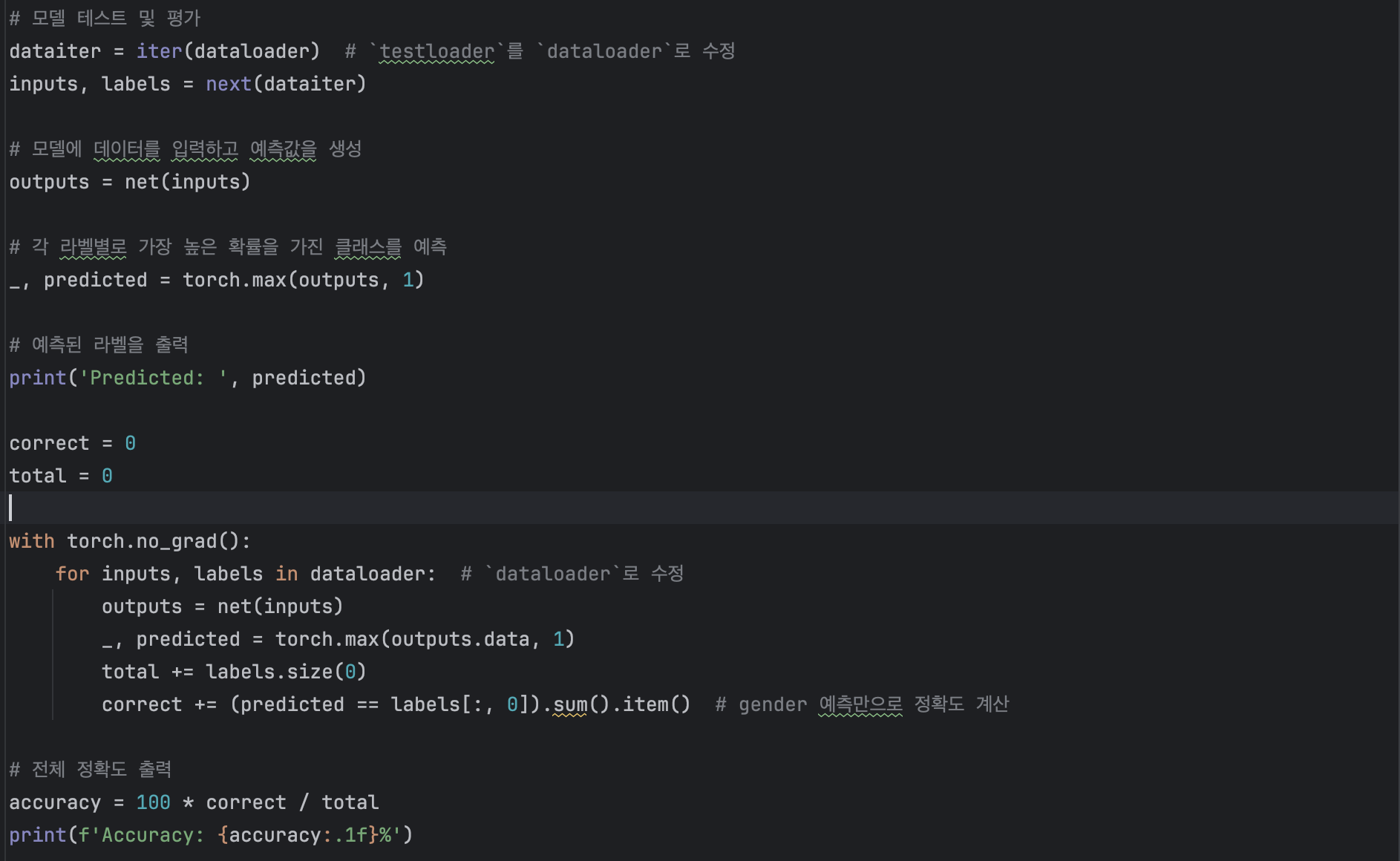
글의 마지막에 다시한번 언급하겠지만 학습 데이터셋에는 여성화자의 음성데이터만 있어 남성화자의 데이터는 학습하지 못했습니다.

test data에 대한 정확도가 100%가 나왔습니다.
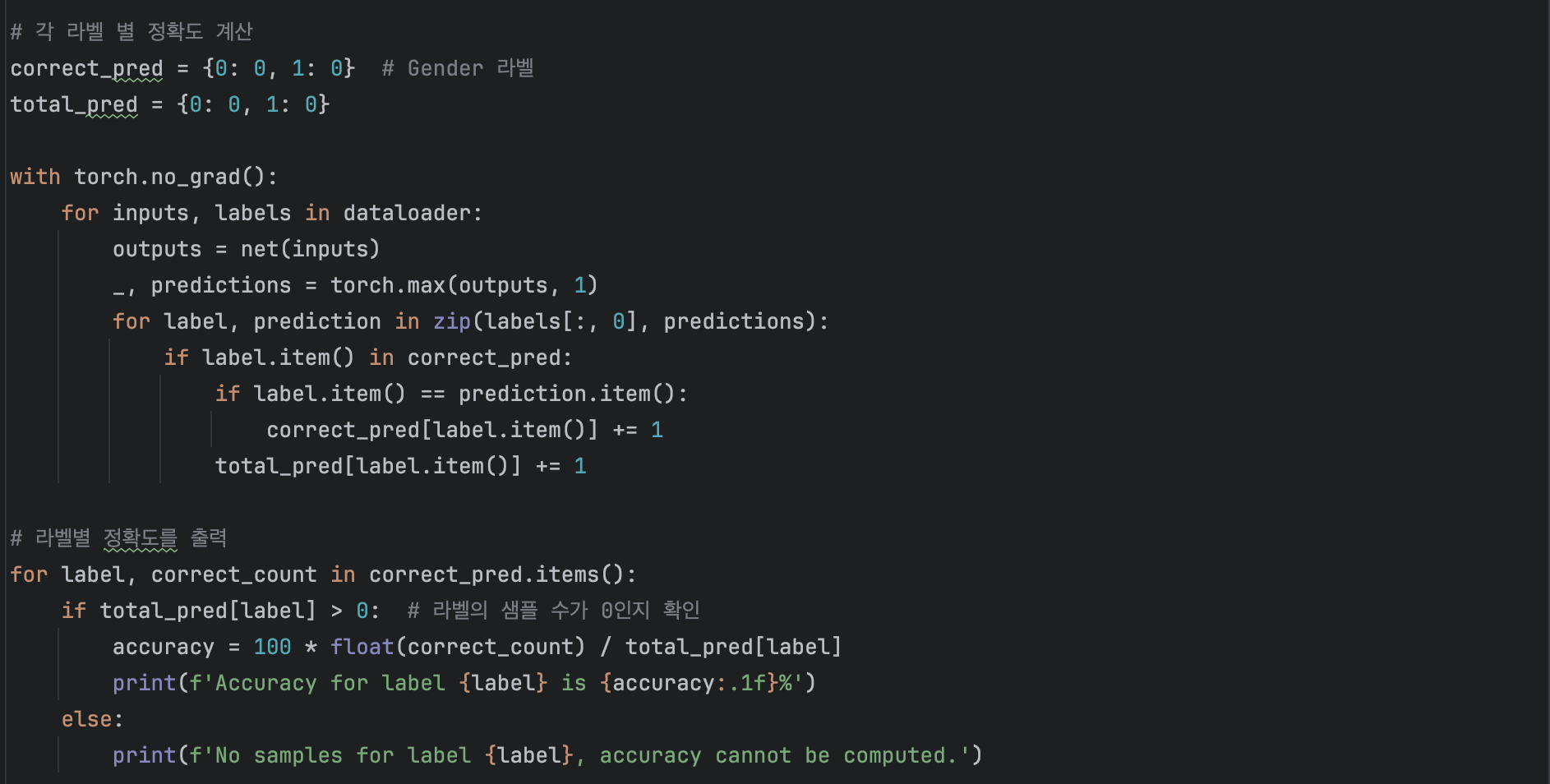
여성의 데이터만 사용했다는 점, 그리고 어떤 문제인지 정확도가 100%가 나온점, 연령 예측에 대한 결과를 얻지 못한 점 등의 문제가 있었습니다. 향후 라이브러리 프로젝트를 위해 만들 유틸리티 클래스와 관련해서는 이러한 문제들을 해결해야 할 것으로 보입니다.
'모각코' 카테고리의 다른 글
| Daiv 모각코 #6 (0) | 2024.08.17 |
|---|---|
| Daiv 모각코 #4 v2 (0) | 2024.07.31 |
| 모각코 #3 v2 (0) | 2024.07.21 |
| Daiv 모각코 #2 v2 (0) | 2024.07.14 |
| Daiv 모각코 #1 v2 (2) | 2024.07.14 |